These services provide local search engine for websites in the form of a free search box implementation code. The web community often asks for SEO best practices for their web sites. Answer (1 of 3): Advantages for crawler operators: * You get to gather the data you want Disadvantages for crawler operators: * Your traffic may be identified as abusive or suspicious and blocked * You may be constrained by your limits in bandwidth, processing, or storage Advantages for https://androbose.in/types-of-search-engines/ In April, news emerged that Microsoft intended to make a huge new investment in web search. This is a very brief history of web server programs, so some information necessarily overlaps with the histories of the web browsers, the World Wide Web and the Internet; therefore, for the sake of the clearness and understandability, some key historical information below reported may be similar to that found also in one or more of the above-mentioned history articles.
engine meta engines msc creator technology ii july fetch.php People search Last Update: May 30, 2022. The Jurisdiction: Germany. I will be needing a 30 page summary about various vertical search engine and web based crawler / scraper. 1.7.1 Crawler-based search engines

User-Agent Switcher Crawl as Googlebot, Bingbot, Yahoo!
Search Engine Crawlers match these terms with the users keywords to show them the results. They select the pages to include in the index randomly. SEO targets unpaid traffic (known as "natural" or "organic" results) rather than direct traffic or paid traffic.Unpaid traffic may originate from different kinds of searches, including image search, video search, academic search, news Scanning means getting a copy of the HTML on each page, and then using this to determine relevance for a search query. WikiMatrix YaCy search engine is based on four elements: Crawler A search robot that traverses from web page to web page and analyzes their content. Crawler-based search engines: such as Google, All The Web and Alta Vista, create their listings automatically by using a piece of software to crawl or spider the web and then index what it finds to build the search base. mnoGoSearch is a crawler, indexer and a search engine written in C and licensed under the GPL (*NIX machines only) Apache Nutch is a highly extensible and scalable web crawler written in Java and released under an Apache License.
What Is A Crawler Based Search Engine? - Lister Info What is a crawler based search engine ideal for?
crawler based search engine 50 Best Open Source Web Crawlers - ProWebScraper LibGuides: Searching the Internet: Types of Search Engines Instagram Crawler 12. 1.1 Major data structural components: Physical architectural component: URL server: A URL server sends the list of URL to the crawler whose information has to be fetched. Go to file T. The Best Onion Sites on the Dark Web in 2021. Contents hide. Now signs of that investment are appearing. The websites that appear in the top positions get thousands of visits from Google on a daily basis. 1. Web crawling is the process of indexing data on web pages by using a program or automated script.


They "crawl" or "spider" the web, then people search thru what they have found. The page where show the result of the search.
Search Engines 
; B2B Search Engine Optimization Ranking high in Google requires
localized infrastructure Nov 20 2017 -- A distributed open source search engine and spider/crawler written in C/C++ for Linux on Intel/AMD. 1.
What is a web crawler? | How web spiders work | Cloudflare One of the first "all text" crawler-based search engines was WebCrawler, which came out in 1994. Crawler search engines rely on sophisticated computer programs called "spiders," "crawlers," or "bots" that surf the Internet, locating webpages, links, and other content that are then stored in the SE's page repository. It is one of the best web crawler which helps you to analyze and audit technical and onsite SEO.
Crawler Based Search Engine for Software Professionals A search engine is a software system designed to carry out web searches.They search the World Wide Web in a systematic way for particular information specified in a textual web search query.The search results are generally presented in a line of results, often referred to as search engine results pages (SERPs).
Web Crawler the difference between web crawler and search engine Search engines (Sullivan, 2001) 3 .
engine engines human powered directories based generically describe often term both optimization spider architecture web Open Source Web Crawler in Python: 1. Optimisation pour les moteurs de recherche (OMR) : modification dun site Web afin quil donne de bons rsultats dans le rfrencement organique des robots de recherche . It has the search bar and use AJAX to give suggestion mechanism. Ask: It was launched in 1996 and was originally known as Ask Jeeves. What is a web crawler? Pages are ranked by a mathematical formula called an algorithm. A user makes a single query request which is distributed to the search engines, databases or other query engines participating in the federation.The federated search then aggregates the results that are received from the search engines for Not only the web, Google fulfill your hunt for the images, videos, news, books, maps, apps etc. They are not organized by subject categories; a computer algorithm ranks all pages.
Search Engine Date published June 30, 2003 Categories.
UConn CSE 4904 - Crawler Based Search Engine - D417018 You can extract data from more than one page, keywords, and categories.
 Microsoft's MSN Search To Build Crawler-Based Search Engine
Microsoft's MSN Search To Build Crawler-Based Search Engine This process is called "crawling" or "spidering". crawler-based-search-engine. Sort by lot #, time remaining, manufacturer, model, year, VIN, and location. Search Engine Optimization (SEO): the act of altering a website so that it does well in the organic, crawler-based listings of search engines. Metasearch engines take input from a user and immediately query search engines for results.
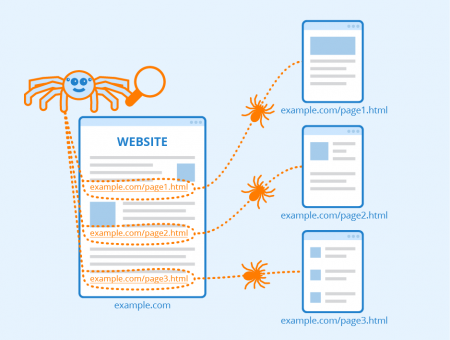
15 Best FREE Website Crawler Tools & Software (2022 Update) There are four distinct phases involved in displaying any sites in crawler based search engine results: Crawling: search engines crawl the whole web to find the web pages available The spider visits a web page, reads it, and then follows links to other pages within the site. A search interface is built in that provides better results than any NZB site or Usenet search engine.
 Inilah Beberapa Jenis Search Engine Yang Marketer Perlu Search Engine
Inilah Beberapa Jenis Search Engine Yang Marketer Perlu Search Engine All commercial search engine crawlers begin crawling a website by downloading its robots.txt file, which contains rules about what pages search engines should or should not crawl on the website.
search Engine City Indexes; Village Indexes; Township Indexes; Subdivision Indexes; Condominium Indexes; Plats. A search engine is an information retrieval system designed to help find information stored on a computer system.The search results are usually presented in a list and are commonly called hits.Search engines help to minimize the time required to find information and the amount of information which must be consulted, akin to other techniques for managing information Find problems and issues that slow down the growth of organic search traffic. real-time search engines) may collect and assess items at the time of the search query, dynamically considering additional items based on the contents of a starting item (known as a seed, or seed URL in the case of an Internet crawler).
Crawler Based  Crawler
Crawler Crawling.
Crawler Based Search Engines Examples Microsoft's MSN Search is still determining how it will evolve, but a key feature is running its own crawler-based search engine in house.
crawler 3. Googlebot (Google) Amazonbot (Amazon) Bingbot (Bing) Baiduspider (Baidu) DuckDuckBot (DuckDuckGo) Yahoo! Industry. Image search is a specialized data search used to find images. In the process of doing so, the search engine analyzes that page's contents. Screaming Frog is a website crawler that enables you to crawl the URLs. Crawler-based search engines . The Sitemaps protocol is based on ideas from "Crawler-friendly Web Servers," Support for the elements that are not required can vary from one search engine to another.
crawling crawl indexing funzionano ranking billionaire determines It is based on Apache Hadoop and can be used with Apache Solr or Elasticsearch. Google is the most used search engine worldwide with a 92 percent market share in mid-2019.
search engines WebHarvy is a website crawling tool that helps you to extract HTML, images, text, and URLs from the site. Crawler-based search engines use "crawlers" or "spiders" to surf the web automatically.
Different types of Search Engines - Lookeen It gets search results from Bing, Yandex, Yahoo and
search-engine The Crawler-Based Search Engines. The bots from the major search engines are called:Google: Googlebot (actually two crawlers, Googlebot Desktop and Googlebot Mobile, for desktop and mobile searches)Bing: BingbotYandex (Russian search engine): Yandex BotBaidu (Chinese search engine): Baidu Spider Real Estate Search 1987 to Present; Geographical Indexes prior 1987.
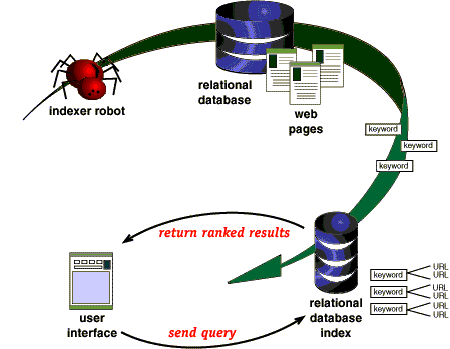
crawlers Crawler Web or Internet search engines look for entered keywords in a web site index A web crawler finds information to put even the index file.
crawler 
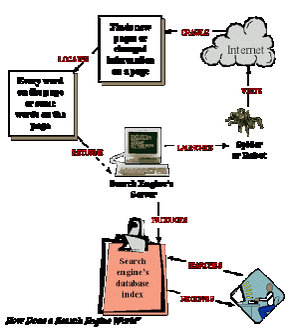
Yahoo! A web crawler, spider, or search engine bot downloads and indexes content from all over the Internet. Dark. Google and Yahoo are examples of crawler search engines. There are four basic steps, every crawler based search engines follow before displaying any sites in the search results.
What is Search Engine and Its Types Real-Time Cloud-Based Website Crawler for Technical SEO Audit Crawl the website for technical issues and get a prioritized to-do list with detailed guides on how to fix errors. Crawler Based Search Engines 1.1.
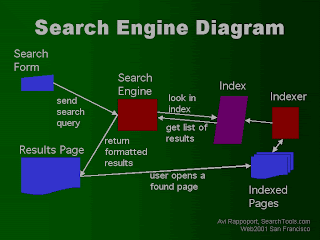
crawler-based search engine - English definition, grammar Also called the spider. Features: This free website crawler can handle form submission, login, etc. A crawler-based search engine, consists of six main components that are crawler, indexer, search index, ranker, query processor, and an Android application for UI support.
Browsers and Search Engines: What overal Optimisation pour les moteurs de recherche (OMR) : modification dun site Web afin quil donne de bons rsultats dans le rfrencement organique des robots de recherche . The information may be a mix of links to web pages, images, Python script solution that captures/craws data from Instagram. Search engines are just index of websites which are mainly created by software known as web crawlers and the spiders. A piece of software called a crawler 1.2. Click on a search engine to highlight its network or filter by Search Engine type using the buttons below: Crawler; On the Search Engine Map the connections between search engines are based on where they get their organic results from.
Search Engine Marketing techwiser qwant Program yang digunakan oleh mesin pencari untuk mengakses laman web disebut spider, namun pada kondisi tertentu dikenal dengan nama lain seperti crawler, robot atau bot.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}