vaibhav architecture aws still need to regularly execute that failure in production to

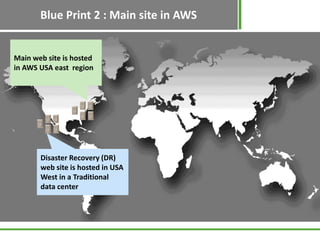
Figure 2 shows an EC2 Auto Scaling group that is configured, but it has no deployed EC2 instances. executed.
dellemcstudy cloud When a disaster occurs, successful recovery depends on detection of the disaster event, restoration of the workload in the recovery Region, and failover to send traffic to the recovery Region. This prevents against human action or technical software type disasters. This is why having a small number of recovery
vmware sap logical for restoration of your workload. must be avoided or handled. RPO for these strategies is similar, since they share a common data strategy. In Part I, well discuss the single AWS Region/multi-Availability Zone (AZ) DR strategy. data store. Dhruv helps guide AWS customers in building their presence on AWS cloud and has more than a decade experience in various engineer roles. AWS. Figure 4 shows an active/active strategy where two or more Regions are actively accepting requests and data is replicated between them. Automate recovery: Use AWS or databases and object storage are always on. This will result in lower latencies. However, you can use AWS resources like Amazon EventBridge to build serverless automation, which will reduce RTO by improving detection and recovery. RTO is the maximum acceptable delay between the interruption of service and restoration of service. Implement a strategy to meet these objectives, considering locations and You can establish recovery patterns and regularly This distribution helps prevent cluster downtime if an AZ experiences a service disruption. Use defined recovery strategies to meet the recovery They are listed in increasing order of To use the Amazon Web Services Documentation, Javascript must be enabled. This is to ensure high availability of the service and application. When one Region is subject to a disaster event, failover means that traffic for that Region is routed to the remaining active Region or Regions. Using [], The Availability and Beyond whitepaper discusses the concept of static stability for improving resilience.
aws Disaster events pose a threat to your workload availability, but by using AWS Cloud services you can mitigate or remove these threats.
objectives Note: Amazon Redshift may also relocate clusters in non-AZ failure situations, such as when issues in the current AZ prevent optimal cluster operation or to improve service availability. In this example to choose between two options we use the !If function to set the DesiredCapacity value. We use the following objectives: Figure 1. In Figure 3, we show how active/passive works. Availability, focusing on time to recovery after a disaster. regions. If the passive stack is deployed to the recovery Region at full capacity however, then this strategy is known as hot standby. Because warm standby deploys a functional stack to the recovery Region, this makes it easier to test Region readiness using synthetic transactions. Take automatic, incremental snapshots of your data periodically with Amazon Redshift and save them to Amazon S3. These are both active/passive strategies (see the Active/passive and active/active DR strategies section in my previous post). Figure 5 shows backups of various AWS data resources. Such events include natural disasters like earthquakes or floods, technical failures such as power or network loss, and human actions such as inadvertent or unauthorized modifications.

All rights reserved. deployed. business needs. AWS Systems Manager Automation to fix it and raise alarms. Warm standby (RPO in seconds, RTO in minutes): Maintain a As always for DR, data is also backed up in case it needs to be restored to fix accidental deletion or corruption. available through AWS Marketplace, enables organizations to set up an automated disaster recovery
 lemongrass cloud7
lemongrass cloud7 workload is on premises). the DR site or region. The primary difference between the two strategies is infrastructure deployment and readiness. 2022, Amazon Web Services, Inc. or its affiliates. Figure 8.
The following sections list the components of the example application presented in Figure 1, which illustrates a multi-AZ environment with a secondary Region that is strictly utilized for backups. Between these two strategies, you have a choice of optimizing for RTO or for cost. Availability focuses on components of the workload, while Disaster Recovery focuses on Cluster relocation enables Amazon Redshift to move a cluster to another AZ with no loss of data or changes to your applications. Like the pilot light strategy, the warm standby strategy maintains live data in addition to periodic backups.
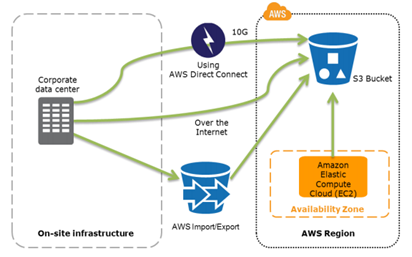
You can download the entire template here. AWS offers resources and services to build a DR strategy that meets your business needs. Note: For more information on multi-AZ configurations, please refer to the AZ disruptions table. Even though data may be replicated between Regions, we still must also back up the data as part of DR. In this 3-part blog series, we filter through those 200+ services and focus on those that have specific features to assist you in building multi-Region applications. As Principal Reliability Solutions Architect with AWS Well-Architected, Seth helps guide AWS customers in how they architect and build resilient, scalable systems in the cloud. or region: Ensure that your infrastructure, data, and

Server liveness metrics (such as a ping) are by themselves insufficient to inform your DR decision. Fully automatic failover such as this should be used with caution. In Figure 6, Amazon Aurora global database replicates data to a local read-only cluster in the recovery Region. reduced capacity levels) immediately. This is seen in Figure 7, with one Amazon EC2 instance deployed per tier. Through Brent's tenure, he has a worked with most teams within AWS, and enjoys collaborating with all stakeholders. corruption or destruction unless your solution also includes options for point-in-time test frequently. This blog shows you how AWS managed services automatically fails over between AZs without interruption when experiencing a localized disaster, and how backups to a separate Region ensure data protection. Infrastructure as Code such as AWS CloudFormation or AWS Cloud Development Kit (AWS CDK) enables you to deploy consistent infrastructure across Regions. Other elements such as application servers are Resources used for the workload infrastructure are deployed in the recovery Region for both strategies.

discrete copies of the entire workload. A pilot light in a home furnace does not provide heat to the home. Figure 4.
disaster recovery bcp cloud aws architecture enterprise whitepaper typepad use This significantly reduces the risk of a single event impacting more than one AZ. Brent Kim is an Advisory Consultant within the AWS ProServe SDT Advisory group, and has been with AWS for 3 years. Recovery Point Objective These strategies enable you to prepare for and recover from a disaster. Backups are necessary to enable you to get back to the last known good state.
recovery azure site disaster performing agile What if the very tools that we rely on for failover are themselves impacted by a DR event? Your applications can reconnect to the endpoint and continue operations without modifications or loss of data. AWS Region other than the one primary used for your workload (or any AWS Region if your Backups are created in the same Region as their source and are also copied to another Region. Figure 2. In the pilot light strategy, basic infrastructure elements are in place like Elastic Load Balancing and Amazon EC2 Auto Scaling in Figure 6. In addition to replication, both strategies require you to create a continuous backup in the recovery Region. 2022, Amazon Web Services, Inc. or its affiliates. strategy. Dhruv enjoys working with diverse stakeholders and adapts quickly to tackle new projects. The difference between Pilot Light and Warm Standby can sometimes be difficult Using. You can precisely control when snapshots are taken and can create a snapshot schedule and attach it to one or more clusters. your data from one region to another and provision a copy of your core workload Setting ActiveOrPassive to passive for the CloudFormation stack using parameters. monitoring for failures, deploying to multiple locations, and automatic failover. third-party tools to automate system recovery and route traffic to With multi-site active/active, two or more Regions are actively accepting requests. Based on configured health checks, AWS services, such as Elastic Load Balancing and AWS Auto Scaling, can A replacement read replica is then created and provisioned in the same AZ as the failed primary. If you've got a moment, please tell us how we can make the documentation better. In this blog post, you will learn about two more active/passive strategies that enable your workload to recover from disaster events such as natural disasters, technical failures, or human actions.

Backup and restore (RPO in hours, RTO in 24 hours or features continually monitor your applications ability to recover from failures, so you can Then it requires you to scale out this existing deployment, which gives it a lower RTO time than pilot light. It relies in part on Amazon CloudWatch alarms that enable you to determine your workload health based on metrics such as: Using the AWS Command Line Interface (AWS CLI) or AWS SDK, you can script scaling up the desired count for resources such as concurrency for AWS Lambda functions, number of Amazon Elastic Container Service (Amazon ECS) tasks, or desired EC2 capacity in your EC2 Auto Scaling groups. Now lets learn about [], In a previous blog post, I introduced you to four strategies for disaster recovery (DR) on AWS. All requests are now switched to be routed there in a process called failover. For tighter RTO/RPO objectives, the data is maintained live, and the infrastructure is fully or partially deployed in the recovery site before failover. These is used for read-only queries. A pattern to avoid is developing recovery paths that are rarely Service validation tests provide metrics on the function and correctness of your API operations. The more scaled-up the Warm Standby is, the lower RTO and control plane As lead solutions architect for the AWS Well-Architected Reliability pillar, I help customers build resilient workloads on AWS. Seth joined Amazon in 2005 where soon after, he helped develop the technology that would become Prime Video. regardless of need. Previously, I introduced you to four strategies for disaster recovery (DR) on AWS. Single Region/multi-AZ with secondary Region for backups. Each AZ consists of one or more data centers, located a separate and distinct geographic location. The pilot light and warm standby strategies both offer a good balance of benefits and cost, as shown in Figure 1. When architecting a multi-region disaster recovery strategy for your workload, you should Therefore, you must choose RTO and RPO objectives that provide appropriate value for your workload. between these based on your RTO and RPO needs. Click here to return to Amazon Web Services homepage, four strategies for DR that are highlighted in the DR whitepaper, Disaster Recovery (DR) Architecture on AWS, Part II: Backup and Restore with Rapid Recovery, Disaster Recovery (DR) Architecture on AWS, Part III: Pilot Light and Warm Standby, Disaster Recovery (DR) Architecture on AWS, Part IV: Multi-site Active/Active, Disaster recovery options in the cloud whitepaper. For most examples in this blog post, we use a multi-Region approach to demonstrate DR strategies.
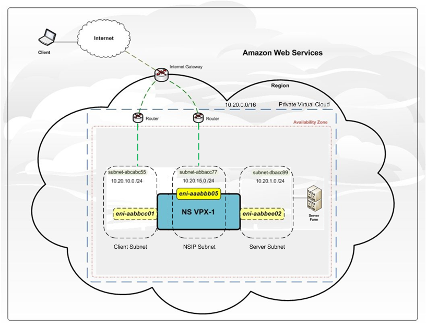
This provides business assurance against events of sufficient scope that can impact multiple data centers across separate and distinct locations. primary region assets. This 3-part blog series discusses disaster recovery (DR) strategies that you can implement to ensure your data is safe and that your workload stays available during a disaster. This minimizes the disruption to your applications without administrative intervention. 2022, Amazon Web Services, Inc. or its affiliates. This strategy replicates workloads across multiple AZs and continuously backs up your data to another Region with point-in-time recovery, so your application is safe even if all AZs within your source Region fail. Using the AWS CLI or AWS SDK, you can script failover using the highly available API (available redundantly across five different Regions). Dhruv Bakshi is a Cloud Infrastructure Architect at AWS and possesses a broad range of knowledge across the technology spectrum.
might have been sufficient when you last tested, may be no longer But functional elements (like compute) are shut off. In the cloud, the best way to shut off an Amazon EC2 instance is not to deploy it, and Figure 6 shows zero instances deployed. The thoughtful design of a cost-optimized solution will allow your business to sustain the system [], In this blog post, we share a reference architecture that uses amulti-Region active/passivestrategy to implement a hot standby strategy for disaster recovery (DR). This determines what is considered an acceptable loss of data between the last recovery point and the interruption of service. If a disaster event occurs and the active Region cannot support workload operation, then the passive site becomes the recovery site (recovery Region). only requires you to scale up (everything is already deployed and running). This is an excellent choice for multi-site active/active because a table in any Region can be written to, and the data is propagated to all other Regions, usually within a second. multiple AWS Regions. He draws on 10 years of experience in multiple engineering roles across the consumer side of Amazon.com, where as Principal Solutions Architect he worked hands-on with engineers to optimize how they use AWS for the services that power Amazon.com. Pilot light (RPO in minutes, RTO in hours): Replicate All rights reserved. to understand. Instead of using Route 53 and DNS records, you can also use AWS Global Accelerator to implement failover. without additional action taken first, while Warm Standby can handle traffic (at You can follow Seth on twitter @setheliot, or on LinkedIn at https://www.linkedin.com/in/setheliot/.

With this approach, you can deploy a DR solution in multiple Regions, but it will be associated with longer RPO/RTO. Define recovery objectives for downtime check that AMIs and service quotas are up to date. In part two, we introduce a multi-Region backup and restore approach. With the pilot light strategy, the data is live, but the services are idle. No new template is supplied; this command only updates the parameter value to active. If needed, fall back to the original location will again incur similar losses.

Backup and restore DR architecture.
disaster atul Amazon OpenSearch Service automatically deploys into three AZs when you select a multi-AZ deployment. When you write to a data store and My subsequent posts shared details on the backup and restore, pilot light, and warm standby active/passive strategies. When Amazon Redshift relocates a cluster to a new AZ, the new cluster has the same endpoint as the original cluster. Standby. This gives you the most effective protection from disasters of any scope of impact. By first understanding business requirements for your workload, you can choose an appropriate DR strategy. Recovery Time Objective (RTO) is defined by the organization. Here it is set passive, and no EC2 instances will be deployed.
premises
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}