Time-series data is also more unique than general analytical (OLAP) data, in that queries generally have a time component, and queries rarely touch every row in the database. There's no specific guarantee for when that might happen. The materialized view is populated with a SELECT statement and that SELECT can join multiple tables. For testing query performance, we used a "standard" dataset that queries data for 4,000 hosts over a three-day period, with a total of 100 million rows. But, as time has marched on and we see more developers use Kubernetes and modular infrastructure setups without lots of specialized storage and memory optimizations, it felt more genuine to benchmark each database on instances that more closely matched what we tend to see in the wild. If you're interested in helping us with these kinds of problems, we're hiring! Timeline of ClickHouse development (Full history here.). Queries are relatively rare (usually hundreds of queries per server or less per second). More importantly, this holds true for all data that is stored in ClickHouse, not just the large, analytical focused tables that store something like time-series data, but also the related metadata. For reads, quite a large number of rows are processed from the DB, but only a small subset of columns. Adding even more filters just slows down the query. ClickHouse chose early in its development to utilize SQL as the primary language for managing and querying data. Additional join types available in ClickHouse: LEFT SEMI JOIN and RIGHT SEMI JOIN, a whitelist on join keys, without producing a cartesian product. Subscribe to our

As soon as the truncate is complete, the space is freed up on disk. One last aspect to consider as part of the ClickHouse architecture and its lack of support for transactions is that there is no data consistency in backups. However, when I wrote my query with more than one JOIN.
repeated querying unions query Our database has three tables named student, enrollment, and payment. You can see this in our other detailed benchmarks vs. AWS Timestream (29 minute read), MongoDB (19 minute read), and InfluxDB (26 minute read). Here is an example: #532 (comment). Just creating the column is not enough though, since old data queries would still resort to using a JSONExtract. The one set of queries that ClickHouse consistently bested TimescaleDB in query latency was in the double rollup queries that aggregate metrics by time and another dimension (e.g., GROUPBY time, deviceId). Specifically, more than one JOIN in a query is currently not allowed.
fdw compile Thank you for taking the time to read our detailed report. We simply installed it per their documentation. How Do You Write a SELECT Statement in SQL?
sql appreciated There is one large table per query. There is at least one other problem with how distributed data is handled. You want to join tables on multiple columns by using a primary compound key in one table and a foreign compound key in another. In our experience running benchmarks in the past, we found that this cardinality and row count works well as a representative dataset for benchmarking because it allows us to run many ingest and query cycles across each database in a few hours. As a result, several MergeTree table engines exist to solve this deficiency - to solve for common scenarios where frequent data modifications would otherwise be necessary. Want to host TimescaleDB yourself? When we ran TimescaleDB without compression, ClickHouse did outperform. TimescaleDB is the leading relational database for time-series, built on PostgreSQL. How can we join the tables with these compound keys? Traditional OLTP databases often can't handle millions of transactions per second or provide effective means of storing and maintaining the data. Could your application benefit from the ability to search using trigrams? Add the PostGIS extension. Learn more about how TimescaleDB works, compare versions, and get technical guidance and tutorials. Already on GitHub? Here is one solution that the ClickHouse documentation provides, modified for our sample data. Join our Slack community to ask questions, get advice, and connect with other developers (the authors of this post, as well as our co-founders, engineers, and passionate community members are active on all channels).

You can find the code for this here and here. In real-world situations, like ETL processing that utilizes staging tables, a `TRUNCATE` wouldn't actually free the staging table data immediately - which could cause you to modify your current processes. Here's how you can use DEFAULT type columns to backfill more efficiently: This will compute and store only the mat_$current_url in our time range and is much more efficient than OPTIMIZE TABLE. It turns out, however, that the files only get marked for deletion and the disk space is freed up at a later, unspecified time in the background. In the first part, we use the student_id column from the enrollment table and student_id from the payment table.
columns excel rows together join multiple merge combine into screenshot larger As a product, we're only scratching the surface of what ClickHouse can do to power product analytics. ZDiTect.com All Rights Reserved. Instead, because all data is stored in primary key order, the primary index stores the value of the primary key every N-th row (called index_granularity, 8192 by default). This would get rid of the JSON parsing and reduce the amount of data read from disk. document.write(d.getFullYear())
So we take great pains to really understand the technologies we are comparing against - and also to point out places where the other technology shines (and where TimescaleDB may fall short). If something breaks during a multi-part insert to a table with materialized views, the end result is an inconsistent state of your data. Other tables can supply data for transformations but the view will not react to inserts on those tables. ClickHouse supports speeding up queries using materialized columns to create new columns on the fly from existing data.

Doing more complex double rollups, ClickHouse outperforms TimescaleDB every time. From this we can see that the ClickHouse server CPU is spending most of its time parsing JSON. In the end, these were the performance numbers for ingesting pre-generated time-series data from the TSBS client machine into each database using a batch size of 5,000 rows. https://clickhouse.yandex/reference_en.html, https://clickhouse.yandex/docs/en/roadmap/, can not cross join three tables(numbers()), you need to list all selected columns. Sure, we can always throw more hardware and resources to help spike numbers, but that often doesn't help convey what most real-world applications can expect. Yet every database is architected differently, and as a result, has different advantages and disadvantages. When selecting rows based on a threshold, TimescaleDB demonstrates between 249-357% the performance of ClickHouse when computing thresholds for a single device, but only 130-58% the performance of ClickHouse when computing thresholds for all devices for a random time window. But if you find yourself doing a lot of construction, by all means, get a bulldozer.. Unlike a traditional OLTP, BTree index which knows how to locate any row in a table, the ClickHouse primary index is sparse in nature, meaning that it does not have a pointer to the location of every value for the primary index. This is the basic case of what ARRAY JOIN clause does. Notice that with numerical numbers, you can get the "correct" answer by multiplying all values by the Sign column and adding a HAVING clause.
Also, PostgreSQL isnt just an OLTP database: its the fastest growing and most loved OLTP database (DB-Engines, StackOverflow 2021 Developer Survey). Let's dig in to understand why. You signed in with another tab or window. It's hard to find now where it has been fixed.
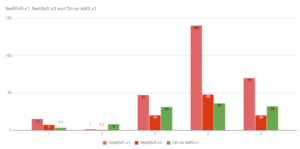
clickhouse redshift altinity benchmark :] select * from t1; SELECT * FROM t1 xy 1 aaa xy 2 bbb Progress: 2.00 rows, 32.00 B (635.66 rows/s., 10.17 KB/s.) Before compression, it's easy to see that TimescaleDB continually consumes the same amount of disk space regardless of the batch size. The data is automatically filled during INSERT statements, so data ingestion doesn't need to change.
sql constraint As an example, consider a common database design pattern where the most recent values of a sensor are stored alongside the long-term time-series table for fast lookup. Lets show each students name, course code, and payment status and amount. How to speed up ClickHouse queries using materialized columns, -- Wait for mutations to finish before running this, The data is passed from users - meaning wed end up with millions (!) ClickHouse, short for Clickstream Data Warehouse, is a columnar OLAP database that was initially built for web analytics in Yandex Metrica.
Sign in It's unique from more traditional business-type (OLTP) data in at least two primary ways: it is primarily insert heavy and the scale of the data grows at an unceasing rate. Timescale's developer advocate Ryan Booz reflects on the PostgreSQL community and shares five ideas on how to improve it.
 merge excel columns cells combine data without losing column select merged box dialog formulas contents
merge excel columns cells combine data without losing column select merged box dialog formulas contents This column separation and sorting implementation make future data retrieval more efficient, particularly when computing aggregates on large ranges of contiguous data. For our tests it was a minor inconvenience. The SELECT TOP statement returns a specified number of records. We are fans of ClickHouse. All tables are small, except for one. ), but not eliminate it completely; its a fact of life for systems. (benchmarking, not benchmarketing). :this is table t1 and t2 data. Finally, depending on the time range being queried, TimescaleDB can be significantly faster (up to 1760%) than ClickHouse for grouped and ordered queries. By the way, does this task introduce a cost model ? The SQL SELECT TOP statement is used to retrieve records from one or more tables in a database and limit the number of records returned based on a fixed value or percentage. With ClickHouse, it's just more work to manage this kind of data workflow. As a developer, you should choose the right tool for the job. Have a question about this project? All tables in ClickHouse are immutable. TimescaleDB was around 3486% faster than ClickHouse when searching for the most recent values (lastpoint) for each item in the database. We help you build better products faster, without user data ever leaving your infrastructure. Were also database nerds at heart who really enjoy learning about and digging into other systems. In our benchmark, TimescaleDB demonstrates 156% the performance of ClickHouse when aggregating 8 metrics across 4000 devices, and 164% when aggregating 8 metrics across 10,000 devices. In some complex queries, particularly those that do complex grouping aggregations, ClickHouse is hard to beat. (In contrast, in row-oriented storage, used by nearly all OLTP databases, data for the same table row is stored together.). Other properties which have lower cardinality can achieve even better compression (weve seen up to 100x)! 6. At a high level, MergeTree allows data to be written and stored very quickly to multiple immutable files (called "parts" by ClickHouse). We also set synchronous_commit=off in postgresql.conf. Here are some of the key aspects of their architecture: First, ClickHouse (like nearly all OLAP databases) is column-oriented (or columnar), meaning that data for the same table column is stored together. Enter your email to receive our newsletter for the latest updates. PostHog is an open source analytics platform you can host yourself. Easy! Regardless of batch size, TimescaleDB consistently consumed ~19GB of disk space with each data ingest benchmark before compression.
We'll go into a bit more detail below on why this might be, but this also wasn't completely unexpected. 1. The typical solution would be to extract $current_url to a separate column.
join column inner tables columns based sql Again, this is by design, so there's nothing specifically wrong with what's happening in ClickHouse!
You can write multi-way join even right now, but it requires explicit additional subqueries with two-way joins of inner subquery and Nth table. ClickHouse will then asynchronously delete rows with a `Sign` that cancel each other out (a value of 1 vs -1), leaving the most recent state in the database. One of the key takeaways from this last set of queries is that the features provided by a database can have a material impact on the performance of your application. The SQL SELECT TOP Clause. ClickHouse was designed for OLAP workloads, which have specific characteristics. For the last decade, the storage challenge was mitigated by numerous NoSQL architectures, while still failing to effectively deal with the query and analytics required of time-series data. Unlike inserts, which primarily vary on cardinality size (and perhaps batch size), the universe of possible queries is essentially infinite, especially with a language as powerful as SQL. In previous benchmarks, we've used bigger machines with specialized RAID storage, which is a very typical setup for a production database environment.
clickhouse The story does change a bit, however, when you consider that ClickHouse is designed to save every "transaction" of ingested rows as separate files (to be merged later using the MergeTree architecture). In response, databases are built with an array of mechanisms to further reduce such risk, including streaming replication to replicas, full-snapshot backup and recovery, streaming backups, robust data export tools, etc. Check. Asterisks (* / t.*) do not work, complex aliases in JOIN ON section do not work. Non SQL Server databases use keywords like LIMIT, OFFSET, and ROWNUM. Since I'm a layman in database/ClickHouse.
Overall, ClickHouse handles basic SQL queries well. Most actions in ClickHouse are not synchronous. At the end of each cycle, we would `TRUNCATE` the database in each server, expecting the disk space to be released quickly so that we could start the next test. The lack of transactions and data consistency also affects other features like materialized views because the server can't atomically update multiple tables at once. In practice, ClickHouse compresses data well, making this a worthwhile trade-off.

There are batch deletes and updates available to clean up or modify data, for example, to comply with GDPR, but not for regular workloads. Often, the best way to benchmark read latency is to do it with the actual queries you plan to execute. PostgreSQL supports a variety of data types including arrays, JSON, and more. Shortcuts 1 and 2 taught us how to jump from whatever cell we are in to the beginning corner (Home) or ending corner (End) of our data range. Alternative syntax for CROSS JOIN is specifying multiple tables in FROM clause separated by commas.
clickhouse What our results didn't show is that queries that read from an uncompressed chunk (the most recent chunk) are 17x faster than ClickHouse, averaging 64ms per query. It's just something to be aware of when comparing ClickHouse to something like PostgreSQL and TimescaleDB. of unique columns, This would complicate live data ingestion a lot, introducing new and exciting race conditions.

PostgreSQL (and TimescaleDB) is like a car: versatile, reliable, and useful in most situations you will face in your life. Execution improvements are also planned, but in previous comment I meant only syntax. This table can be used to store a lot of analytics data and is similar to what we use at PostHog. Today we live in the golden age of databases: there are so many databases that all these lines (OLTP/OLAP/time-series/etc.) Column-oriented storage has a few advantages: To improve the storage and processing of data in ClickHouse, columnar data storage is implemented using a collection of table "engines". The parameters added to the Decimal32(p) are the precision of the decimal digits for e.g Decimal32(5) can contain numbers from -99999.99999 to 99999.99999. For simple rollups (i.e., single-groupby), when aggregating one metric across a single host for 1 or 12 hours, or multiple metrics across one or multiple hosts (either for 1 hour or 12 hours), TimescaleDB generally outperforms ClickHouse at both low and high cardinality. Because ClickHouse does not support transactions and data is in a constant state of being moved, there is no guarantee of consistency in the state of the cluster nodes. Clearly ClickHouse is designed with a very specific workload in mind. Were always interested in feedback, and well continue to share our insights with the greater community. This impacts both data collection and storage, as well as how we analyze the values themselves. For example, if # of rows in table A = 100 and # of rows in table B = 5, a CROSS JOIN between the 2 tables (A * B) would return 500 rows total.
Choosing the best technology for your situation now can make all the difference down the road.

If we wanted to query login page pageviews in August, the query would look like this: This query takes a while complete on a large test dataset, but without the URL filter the query is almost instant.

Also, through the use of extensions, PostgreSQL can retain the things it's good at while adding specific functionality to enhance the ROI of your development efforts. Again, the value here is that MergeTree tables provide really fast ingestion of data at the expense of transactions and simple concepts like UPDATE and DELETE in the way traditional applications would try to use a table like this. (A proper ClickHouse vs. PostgreSQL comparison would probably take another 8,000 words.
clickhouse (For one specific example of the powerful extensibility of PostgreSQL, please read how our engineering team built functional programming into PostgreSQL using customer operators.). Based on ClickHouses reputation as a fast OLAP database, we expected ClickHouse to outperform TimescaleDB for nearly all queries in the benchmark. Vectorized computing also provides an opportunity to write more efficient code that utilizes modern SIMD processors, and keeps code and data closer together for better memory access patterns, too. Lets now understand why PostgreSQL is so loved for transactional workloads: versatility, extensibility, and reliability. That said, as you'll see from the benchmark results, enabling compression in TimescaleDB (which converts data into compressed columnar storage), improves the query performance of many aggregate queries in ways that are even better than ClickHouse. There is no way to directly update or delete a value that's already been stored. The difference is that TimescaleDB gives you control over which chunks are compressed. We find that in our industry there is far too much vendor-biased benchmarketing and not enough honest benchmarking. We believe developers deserve better. Dictionaries are plugged to external sources. The typical way to do this in SQL Server 2005 and up is to use a CTE and windowing functions. Thank you for all your attention. Instead, if you find yourself needing something more versatile, that works well for powering applications with many users and likely frequent updates/deletes, i.e., OLTP, PostgreSQL may be the better choice. Generally in databases there are two types of fundamental architectures, each with strengths and weaknesses: OnLine Transactional Processing (OLTP) and OnLine Analytical Processing (OLAP). At a high level, ClickHouse is an excellent OLAP database designed for systems of analysis. Indeed, joining many tables is currently not very convenient but there are plans to improve the join syntax. As you (hopefully) will see, we spent a lot of time in understanding ClickHouse for this comparison: first, to make sure we were conducting the benchmark the right way so that we were fair to Clickhouse; but also, because we are database nerds at heart and were genuinely curious to learn how ClickHouse was built. Does your application need geospatial data? This is what the lastpoint and groupby-orderby-limit queries benchmark. As a result, we wont compare the performance of ClickHouse vs. PostgreSQL because - to continue our analogy from before - it would be like comparing the performance of a bulldozer vs. a car.
sql educba structure When selecting rows based on a threshold, TimescaleDB outperforms ClickHouse and is up to 250% faster. Data cant be directly modified in a table, No index management beyond the primary and secondary indexes, No correlated subqueries or LATERAL joins, 1 remote client machine running TSBS, 1 database server, both in the same cloud datacenter. If something breaks during a multi-part insert to a table with materialized views, the end result is an inconsistent state of your data. Finally, we always view these benchmarking tests as an academic and self-reflective experience. The enrollment table has data in the following columns: primary key (student_id and course_code), is_active, and start_date. 2 Keyboard Shortcuts to Select a Column with Blank Cells. The trade-off is more data being stored on disk. In this detailed post, which is the culmination of 3 months of research and analysis, we answer the most common questions we hear, including: Shout out to Timescale engineers Alexander Kuzmenkov, who was most recently a core developer on ClickHouse, and Aleksander Alekseev, who is also a PostgreSQL contributor, who helped check our work and keep us honest with this post. As an example, if you need to store only the most recent reading of a value, creating a CollapsingMergeTree table type is your best option. In PostgreSQL (and other OLTP databases), this is an atomic action. On our test dataset, mat_$current_url is only 1.5% the size of properties_json on disk with a 10x compression ratio. This means asking for the most recent value of an item still causes a more intense scan of data in OLAP databases. Regardless, the related business data that you may store in ClickHouse to do complex joins and deeper analysis is still in a MergeTree table (or variation of a MergeTree), and therefore, updates or deletes would still require an entire rewrite (through the use of `ALTER TABLE`) any time there are modifications. TIP: SELECT TOP is Microsoft's proprietary version to limit your results and can be used in databases such as SQL Server and MSAccess. To avoid this, you can use TOP 1 WITH TIES.
Specifically, we ran timescaledb-tune and accepted the configuration suggestions which are based on the specifications of the EC2 instance. It is created outside of databases. Sometimes it just works, while other times having the ability to fine-tune how data is stored can be a game-changer. Add TimescaleDB. The payment table has data in the following columns: foreign key (student_id and course_code, the primary keys of the enrollment table), status, and amount. I found very hard to convert all MySQL query into ClickHouse's one. Lack of ability to modify or delete already inserted data with a high rate and low latency. var d = new Date()
For some complex queries, particularly a standard query like "lastpoint", TimescaleDB vastly outperforms ClickHouse. These files are later processed in the background at some point in the future and merged into a larger part with the goal of reducing the total number of parts on disk (fewer files = more efficient data reads later). Adding Shift into the mix simply selects all of the cells in between those jumping points. That is, spending a few hundred hours working with both databases often causes us to consider ways we might improve TimescaleDB (in particular), and thoughtfully consider when we can- and should - say that another database solution is a good option for specific workloads.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}